5.1. User ID Resolvers¶
Each organisation or company usually has its users managed at a central location. This is why privacyIDEA does not provide its own user management but rather connects to existing user stores.
UserIdResolvers are connectors to those user stores, the locations, where the users are managed. Nowadays this can be LDAP directories or especially Active Directory, some times FreeIPA or the Redhat 389 service. But classically users are also located in files like /etc/passwd on standalone unix systems. Web services often use SQL databases as user store.
Today with many more online cloud services SCIM is also an uprising protocol to access userstores.
privacyIDEA already comes with UserIdResolvers to talk to all these user stores:
Note
New resolver types (python modules) can be added easily. See the module section for this (UserIdResolvers).
You can create as many UserIdResolvers as you wish and edit existing resolvers. When you have added all configuration data, most UIs of the UserIdResolvers have a button “Test resolver”, so that you can test your configuration before saving it.
Starting with privacyIDEA 2.4 resolvers can be editable, i.e. you can edit the users in the user store. Read more about this at Manage Users.
Note
Using the authentication policy otppin=userstore users can
authenticate with the password
from their user store, being the LDAP password, SQL password or password
from flat file.
5.1.1. Flatfile Resolver¶
Flatfile resolvers read files like /etc/passwd.
Note
The file /etc/passwd does not contain the unix password.
Thus, if you create a flatfile resolver from this file the functionality
with otppin=userstore is not available. You can create a flatfile with
passwords using the tool privacyidea-create-pwidresolver-user which is
usually found in /opt/privacyidea/bin/.
Create a flat file like this:
privacyidea-create-pwidresolver-user -u user2 -i 1002 >> /your/flat/file
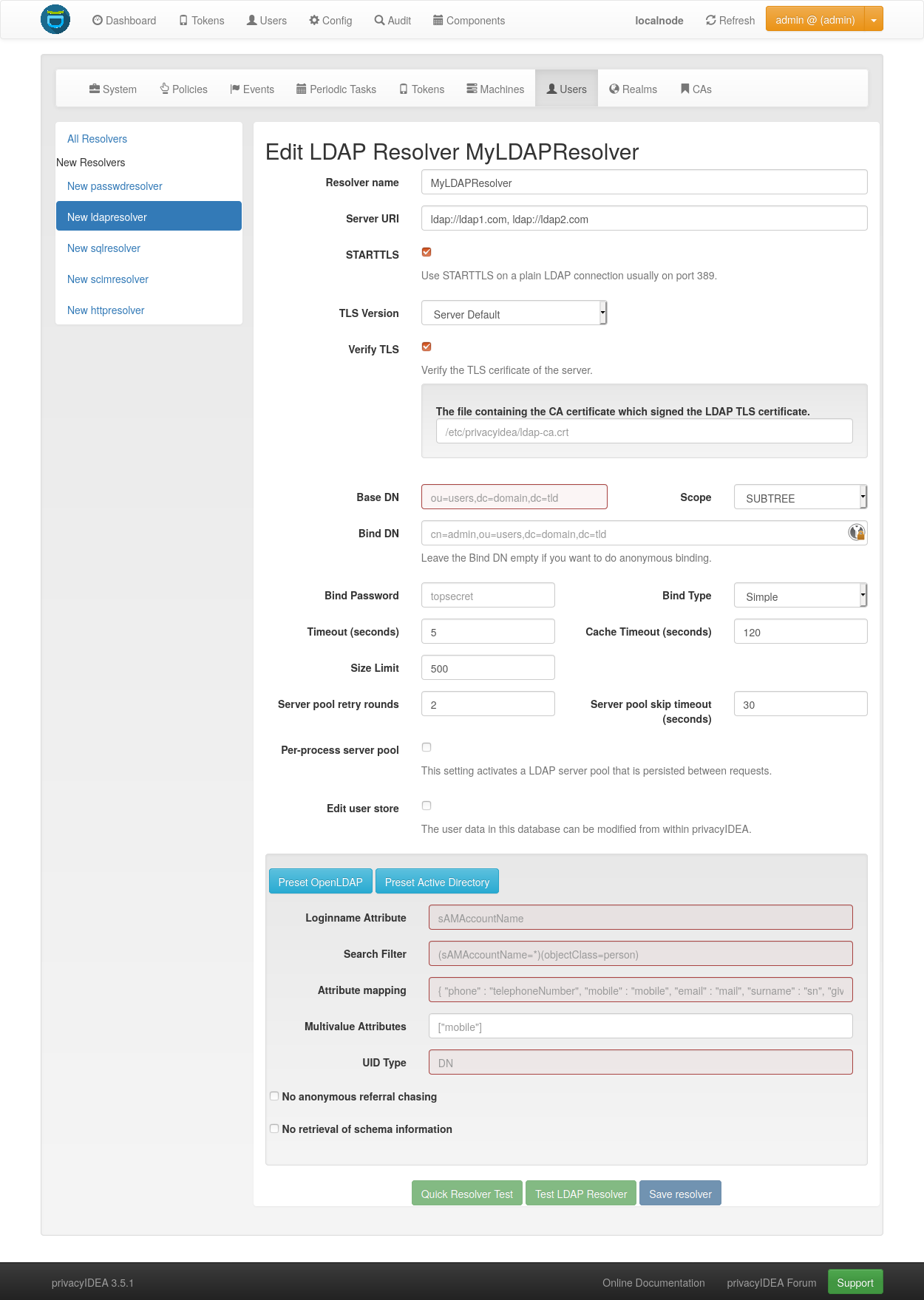
5.1.2. LDAP Resolver¶
The LDAP resolver can be used to access any kind of LDAP service like OpenLDAP, Active Directory, FreeIPA, Penrose, Novell eDirectory.
LDAP resolver configuration¶
5.1.2.1. Server Settings¶
The Server URI can contain a comma separated list of servers.
The servers are used to create a server pool and are used with a round robin
strategy [1].
Example:
ldap://server1, ldaps://server2:1636, server3, ldaps://server4
This will create LDAP requests to
server1 on port 389
server2 on port 1636 using SSL
server3 on port 389
server4 on port 636 using SSL.
5.1.2.1.1. TLS Version¶
When using TLS, you may specify the TLS version to use. Starting from version 3.6, privacyIDEA offers TLS v1.3 by default.
5.1.2.1.2. TLS Certificates¶
When using TLS with LDAP, you can tell privacyIDEA to verify the certificate. The according checkbox is visible in the WebUI if the target URL starts with ldaps or when using STARTTLS.
You can specify a file with the trusted CA certificate, that signed the TLS certificate. The default CA filename is /etc/privacyidea/ldap-ca.crt and can contain a list of base64 encoded CA certificates. PrivacyIDEA will use the CA file if specified. If you leave the field empty it will also try the system certificate store (/etc/ssl/certs/ca-certificates.crt or /etc/ssl/certs/ca-bundle.crt).
5.1.2.1.3. Binding¶
The Bind Type for querying the LDAP-Server can be Anonymous, Simple,
NTLM, SASL Digest-MD5 (Deprecated) or SASL Kerberos.
Note
When using bind type Simple you can specify the Bind-DN like
cn=administrator,cn=users,dc=domain,dc=name or administrator@domain.name.
When using bind type NTLM you need to specify Bind-DN like
DOMAINNAME\\username. In case of SASL Kerberos the Bind-DN needs to
be the PrincipalName corresponding to the given keytab-file.
For the SASL Kerberos bind type, the privacyIDEA server needs to be
integrated into the AD Domain. A basic setup and more information on the Kerberos
authentication can be found in the corresponding
GitHub Wiki.
5.1.2.1.4. Caching¶
The Cache Timeout configures a short living per process cache for LDAP users.
The cache is not shared between different Python processes, if you are running more processes
in Apache or Nginx. You can set this to 0 to deactivate this cache.
5.1.2.1.5. Server Pools¶
The Server pool retry rounds and Server pool skip timeout settings configure the behavior of
the LDAP server pool. When establishing a LDAP connection, the resolver uses a round-robin
strategy to select a LDAP server from the pool. If the current server is not reachable, it is removed
from the pool and will be re-inserted after the number of seconds specified in the skip timeout.
If the pool is empty after a round, a timeout is added before the next round is started.
The ldap3 module defaults system wide to 10 seconds before starting the next round.
This timeout can be changed by setting PI_LDAP_POOLING_LOOP_TIMEOUT to an
integer in seconds in the The Config File.
If no reachable server could be found after the number of rounds specified in the retry rounds,
the request fails.
By default, knowledge about unavailable pool servers is not persisted between requests. Consequently, a new request may retry to reach unavailable servers, even though the skip timeout has not passed yet. If the Per-process server pool is enabled, knowledge about unavailable servers is persisted within each process. This setting may improve performance in situations in which a LDAP server from the pool is down for extended periods of time.
5.1.2.1.6. Modifying Users¶
Starting with privacyIDEA 2.12, you can define the LDAP resolver as editable. I.e. you can create and modify users from within privacyIDEA.
There are two additional configuration parameters for this case.
DN Template defines how the DN of the new LDAP object should be created. You can use username, surname,
givenname and basedn to create the distinguished name.
Examples:
CN=<givenname> <surname>,<basedn>
CN=<username>,OU=external users,<basedn>
uid=<username>,ou=users,o=example,c=com
Object Classes defines which object classes the user should be assigned to. This is a comma separated list.
The usual object classes for Active Directory are:
top, person, organizationalPerson, user, inetOrgPerson
5.1.2.2. Resolver Settings¶
5.1.2.2.1. Loginname Attribute¶
The LoginName attribute is the attribute that holds the login name. It
can be changed to your needs.
Starting with version 2.20 you can provide a list of attributes in
LoginName Attribute like:
sAMAccountName, userPrincipalName
This way a user can login with either his sAMAccountName or his principalName.
5.1.2.2.2. Search Filter¶
The searchfilter is used to list all possible users, that can be used
in this resolver. The search filter is used for forward and backward
search the object in LDAP.
5.1.2.2.3. Attribute Mapping¶
The attribute mapping maps LDAP object attributes to user attributes in
privacyIDEA. privacyIDEA knows the following attributes:
phone,
mobile,
surname,
givenname,
password
accountExpires.
The above attributes are used for privacyIDEA’s normal functionality and are listed in the User Details. However, with a SAML authentication request, the user attributes can be returned. (see Include SAML attributes in the authentication response.). To return arbitrary attributes from the LDAP You can add additional keys to the attribute mapping with a key, you make up and the LDAP attribute like:
"homedir": "homeDirectory",
"studentID": "objectGUID"
"homeDirectory" and "objectGUID" being the attributes in the LDAP directory
and "homedir" and "studentID" the keys returned in a SAML authentication
request.
5.1.2.2.4. Multivalue Attributes¶
The MULTIVALUEATTRIBUTES config value can be used to specify a list of
user attributes, that should return a list of values. Imagine you have a user mapping like
{ "phone" : "telephoneNumber", "email" : "mail", "surname" : "sn", "group": "memberOf"}.
Then you could specify ["email", "group"] as the multi value attribute and the user object
would return the emails and the group memberships of the user from the LDAP server as a list.
Note
If the MULTIVALUEATTRIBUTES is left blank the default setting is “mobile”. I.e. the
mobile number will be returned as a list.
The MULTIVALUEATTRIBUTES can be well used with the samlcheck endpoint (see Validate endpoints)
or with the policy
add_user_in_response.
5.1.2.2.5. UID Type¶
The UID Type is the unique identifier for the LDAP object. If it is left
blank, the distinguished name will be used. In case of OpenLDAP this can be
entryUUID and in case of Active Directory objectGUID. For FreeIPA you
can use ipaUniqueID.
Note
The attributes entryUUID, objectGUID, and ipaUniqueID are case sensitive!
5.1.2.2.6. Recursive Search of User Groups¶
Added in version 3.12.
Active Directory only returns the direct group memberships of a user. If you are using nested groups and are interested in all group memberships, you can use this option. The resolver will then perform another search to retrieve all groups of the user, according to the defined search filter.
Base DN of User Groups
Define the groups container base DN. If your groups are located under the same base DN as defined in Base DN for
the users you can leave this field empty.
Search Filter for User Groups
- Define a search filter to get the groups of the user. The following tags can be used:
{base_dn}: The base DN of the users as defined inBase DN{username}: The username of the user to search forAll keys defined in the attribute mapping surrounded by curly braces
For example, a valid search filter could be:
(&(sAMAccountName=*)(objectCategory=group)(member:1.2.840.113556.1.4.1941:=cn={username},{base_dn}))
The OID 1.2.840.113556.1.4.1941 stands for the LDAP_MATCHING_RULE_IN_CHAIN, flag indicating that the search should
be done recursively. This filter works if the user location is in the Base DN. If this is not the case, you can
add the user location to the attribute mapping, e.g., distinguishedName. Then this attribute can be used as a tag
in the search filter, such as
(&(sAMAccountName=*)(objectCategory=group)(member:1.2.840.113556.1.4.1941:={distinguishedName}))
Group Name Attribute
The LDAP group attribute defining the group’s name, which should be stored in the user info (attribute mapping value),
e.g., distinguishedName.
User Info Key
The key to store the groups in the user info (attribute mapping key).
5.1.2.2.7. No anonymous referral chasing¶
In case of Active Directory connections you might need to check the box
No anonymous referral chasing. The underlying LDAP library is only
able to do anonymous referral chasing. Active Directory will produce an
error in this case [2].
5.1.2.2.8. No retrieval of schema information¶
The option No retrieval of schema information can be used to
disable the retrieval of schema information [4] in
order to improve performance. This checkbox is deactivated by default
and should only be activated after having ensured that schema information
are unnecessary.
5.1.2.3. Expired Users¶
You may set:
"accountExpires": "accountExpires"
in the attribute mapping for Microsoft Active Directories. You can then call
the user listing API with the parameter accountExpires=1 and you will only
see expired accounts.
This functionality is used with the script privacyidea-expired-users.
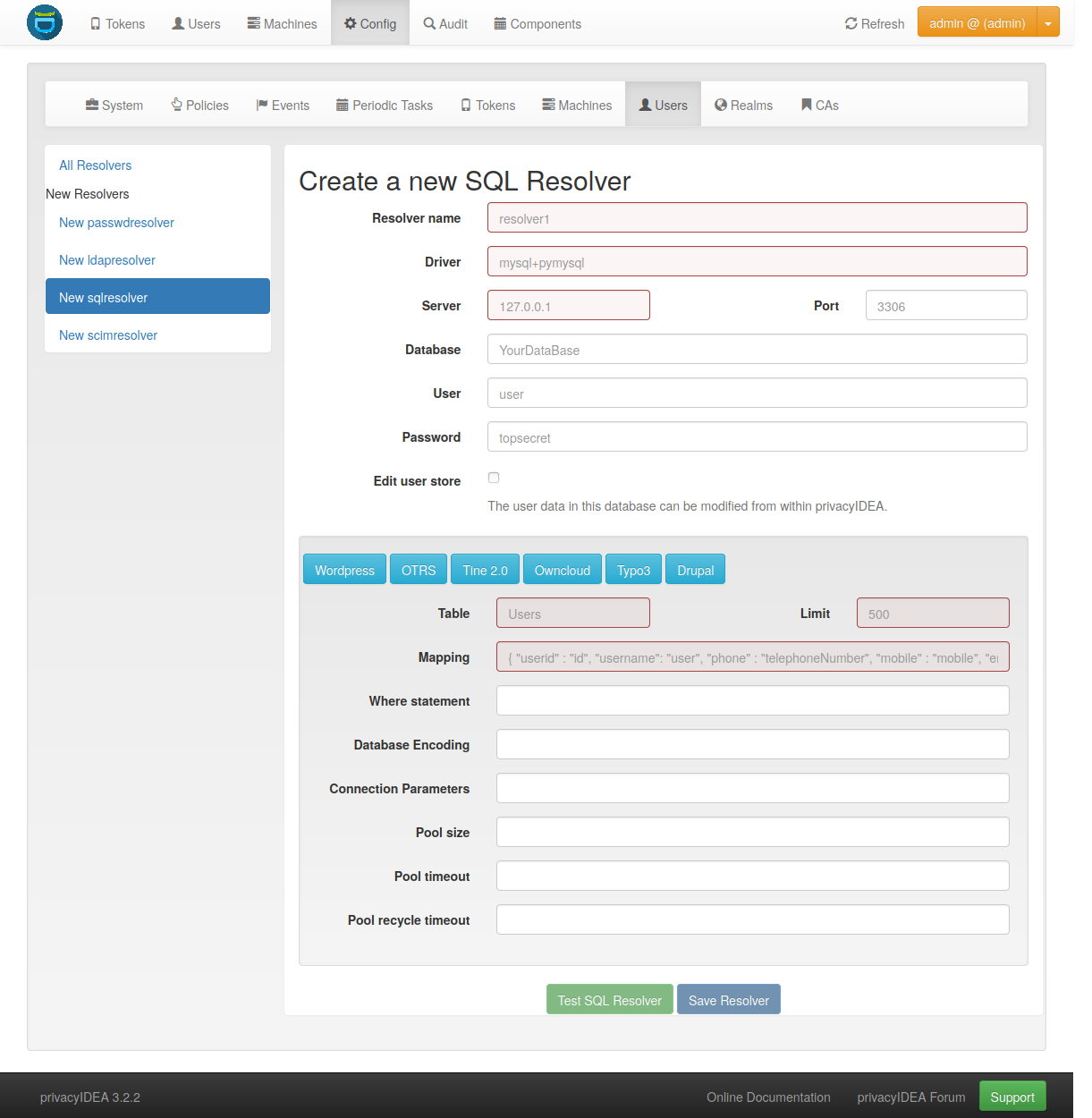
5.1.3. SQL Resolver¶
The SQL resolver can be used to retrieve users from any kind of SQL database like MySQL, PostgreSQL, Oracle, DB2 or sqlite.
SQL resolver configuration¶
In the upper frame you need to configure the SQL connection.
The SQL resolver uses SQLAlchemy internally.
In the field Driver you need to set a driver name as defined by the
SQLAlchemy dialects
like “mysql” or “postgres”.
In the SQL attributes frame you can specify how the users are
identified.
The Database table contains the users.
Note
At the moment, only one table is supported, i.e. if some of the user data like email address or telephone number is located in a second table, those data can not be retrieved.
The Limit is the SQL limit for a userlist request. This can be important
if you have several thousand user entries in the table.
The Attribute mapping defines which table column should be mapped to
which privacyIDEA attribute. The known attributes are:
userid (mandatory),
username (mandatory),
phone,
mobile,
email,
givenname,
surname,
password.
The password attribute is the database column that contains the user
password. This is used, if you are doing user authentication against the SQL
database.
Note
There is no standard way to store passwords in an SQL database. privacyIDEA supports the most common ways like Wordpress hashes starting with $P or $S. Secure hashes starting with {SHA} or salted secure hashes starting with {SSHA}, {SSHA256} or {SSHA512}. Password hashes of length 64 are interpreted as OTRS sha256 hashes.
You can mark the users as Editable. The Password_Hash_Type can be
used to determine which hash algorithm should be used, if a password of an
editable user is written to the database.
You can add an additional Where statement if you do not want to use
all users from the table.
The poolSize and poolTimeout determine the pooling behaviour. The
poolSize (default 5) determine how many connections are kept open in the
pool. The poolTimeout (default 10) specifies how long the application
waits to get a connection from the pool.
Note
The pooling parameters only have an effect if the PI_ENGINE_REGISTRY_CLASS
config option is set to "shared" (see Engine Registry Class).
If you then have several SQL resolvers with the same connection and pooling settings,
they will use the same shared connection pool.
If you change the connection settings of an existing connection, the connection pool
for the old connection settings will persist until the respective connections
are closed by the SQL server or the web server is restarted.
Note
The Additional connection parameters
refer to the SQLAlchemy connection but are not used at the moment.
5.1.4. SCIM Resolver¶
SCIM is a “System for Cross-domain Identity Management”. SCIM is a REST-based protocol that can be used to ease identity management in the cloud.
The SCIM resolver is tested in basic functions with OSIAM [3], the “Open Source Identity & Access Management”.
To connect to a SCIM service you need to provide a URL to an authentication
server and a URL to the resource server. The authentication server is used to
authenticate the privacyIDEA server. The authentication is based on a Client
name and the Secret for this client.
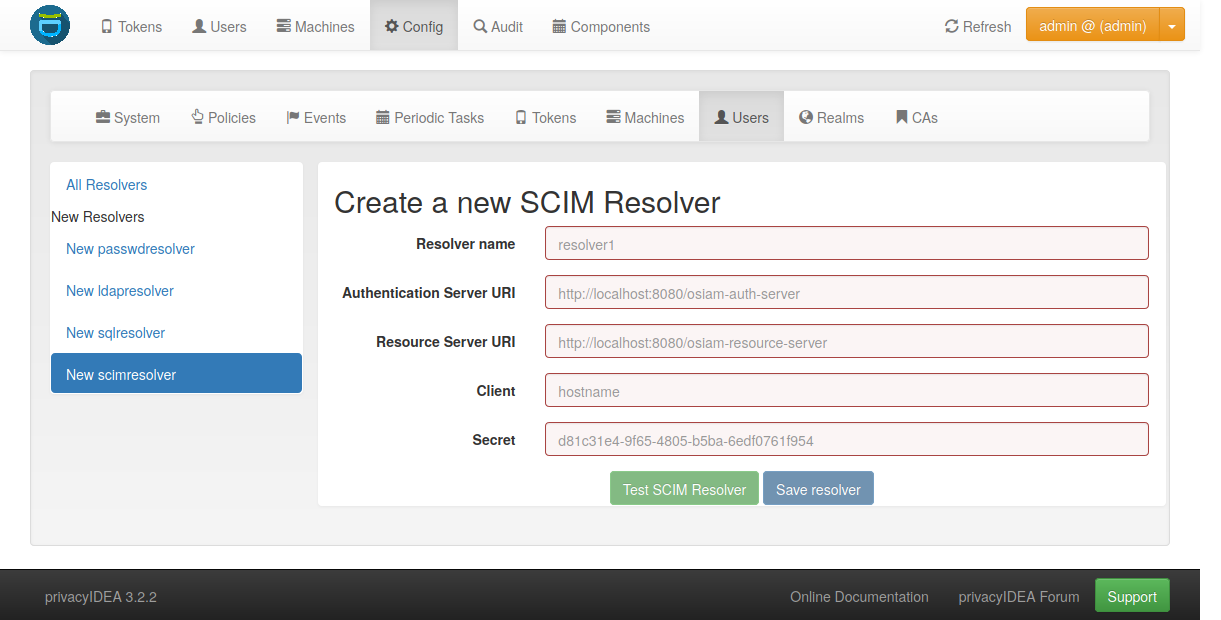
User information is then retrieved from the resource server.
The available attributes for the Attribute mapping are:
username (mandatory),
givenname,
surname,
phone,
mobile,
email.
5.1.5. HTTP Resolver¶
Starting with version 3.4 the HTTP resolver is available to retrieve user information from any kind of web service API. There are four types of HTTP resolvers:
Basic HTTP Resolver: Limited configuration options to retrieve user information for a single user.
Advanced HTTP Resolver: More complex configuration options to not only get user information for different purposes, but also allows to create, edit and delete users.
Entra ID Resolver: Preconfigured advanced HTTP resolver to retrieve user information from Microsoft Entra ID.
Keycloak Resolver: Preconfigured advanced HTTP resolver to retrieve user information from Keycloak.
5.1.5.1. Basic HTTP Resolver¶
privacyIDEA issues a request to the target service and expects a JSON object in return.
The configuration of the HTTP resolver sets the details of the request in the Request Mapping as well as the
mapping of the obtained information as a Response Mapping.

The Request Mapping is used to build the request issued to the remote API from privacyIDEA’s user information.
For example an endpoint definition:
POST /get-user
customerId=<user_id>&accessKey="secr3t!"
will require a request mapping
{ "customerId": "{userid}", "accessKey": "secr3t!" }
The Response Mapping follows the same rules as the attribute mapping of the SQL resolver. The known attributes are
username (mandatory),
givenname,
surname,
phone,
mobile,
email.
Nested attributes are also supported using pydash deep path for parsing, e.g.
{ "username": "{Username}", "email": "{Email}", "phone": "{Phone_Numbers.Phone}" }
For APIs which return 200 OK also for a negative response, Special error handling can be activated to treat
the request as unsuccessful if the response contains certain content.
The above configuration image will throw an error for a response
{ "success": false, "message": "There was an error!" }
because privacyIDEA will match { "success": false }.
Note
If the HTTP response status is >= 400, the resolver will throw an exception.
5.1.5.2. Advanced HTTP Resolver¶
Added in version 3.12.
The advanced HTTP resolver is a more complex version of the basic HTTP resolver. In the UI, first some generic settings are configured. Below that, you can set up the user store API endpoint for each resolver functionality.

- Generic Settings
Resolver name: A unique name for the resolver.
Base URL: The base URL of the user store API. It will be concatenated with the
Endpointin the detailed configurations, except for endpoints where a full URL is specified starting withhttp.Attribute Mapping: Mapping between the user attribute names used by privacyIDEA and the user store API. The known attributes in privacyIDEA are:
username
userid
givenname
surname
phone
mobile
email
Groups: Enable this option to perform a separate request to retrieve the user’s groups. Parameters to configure:
privacyIDEA User Groups Key: The key to store the groups in the user info (attribute mapping key). By default, this is
groups.User Store Group Attribute: The groups attribute from the user store to be used as identifier for the group, e.g.
nameorid.HTTP Method: The HTTP method to use for the request to retrieve the groups (GET, POST, PUT, PATCH, DELETE).
Endpoint: The endpoint of the user store API to retrieve the groups of the user. It will be concatenated with the base URL except if a full URL starting with
httpis specified. Possible tags:{userid}
Headers (optional): Default request header to use if no specific one is defined. It has to be in JSON format, e.g.
{"Content-Type": "application/json"}.Edit user store: If checked, the resolver is editable and allows creating, editing, and deleting users in the user store. Note that these rights must also be granted in the user store.
Verify TLS: If checked, the TLS certificate of the user store API is verified. This should always be checked for productive use! Optionally, a CA certificate can be provided to verify the TLS certificate of the user store API.
Timeout: Time in seconds to wait for a response from the user store API. If the request takes longer, it will be aborted.
Endpoint Configuration
- The configuration is similar for each endpoint:
Method: The HTTP method to use for the request (GET, POST, PUT, PATCH, DELETE)
Endpoint: The endpoint of the user store API to which the request is sent. It will be concatenated with the base URL. If you enter a full URL starting with
http, it will not be concatenated with the base URL. You can use tags to dynamically construct the endpoint, e.g./users/{userid}. Possible tags depend on the endpoint.Headers (optional): Request headers to use for this endpoint. It has to be in JSON format, e.g.
{"Content-Type": "application/json"}. For requests sending JSON data, theContent-Typeheader is set automatically toapplication/json.Request Mapping (optional): The request parameters to send to the user store API. It has to be in JSON format, e.g.
{"username": "{username}", "email": "{email}"}. You can use tags to map the user attributes to the request parameters. Possible tags depend on the endpoint. Note that tags can only be used in strings, hence they must always be surrounded by double quotation marks.If the
Content-Typeheader is set toapplication/x-www-form-urlencoded, the request mapping can be defined as query parameters in the formatkey1=value1&key2=value2.Response Mapping (optional): Reformatting of the response from the user store API to the expected format for privacyIDEA. It has to be in JSON format. You can use the keys of the original response as tags, e.g.
{"username": "{Username}", "email": "{Email}"}. You can also use nested attributes using pydash deep path, e.g.:{ "username": "{Username}", "phone": "{Phone_Numbers.Phone}" }
Note
If both response and attribute mappings are defined, the response mapping is applied first, followed by the attribute mapping on the reformatted response. It is recommended to only use one of these mappings. However, at least one mapping must be used.
Special error handling (optional): If checked, the resolver will treat the request as unsuccessful if the response contains certain content. This is useful for APIs that return
200 OKfor a negative response. The content to match can be defined in theResponse contains.

Authorization
This section allows you to configure an endpoint to which the privacyIDEA server must authenticate in order to receive
an access token. This token can then be used to access the user store API.
Besides the generic endpoint settings, the username and password of a service account can be configured to
authenticate.
The password is stored encrypted in the database. If username and password are defined, they can be used as tags for
the endpoint and request mapping, e.g. {"username": "{username}", "password": "{password}"}.
Check User Password
Configure the endpoint to authenticate the user with their username/userid and password. You can use the tags
{username}, {userid}, and {password} in the endpoint definition and request mapping.
This request does not use the authorization header defined in the previous section.
User List
Configure the endpoint to retrieve a list of users from the user store. The above-defined attributes are added to the
request as search parameters if they are available in the request. You can also use the attributes as tags
({username}, {userid}, {surname}, {givenname}).
Get User by ID
Configure the endpoint to retrieve a single user for the UID. For example, privacyIDEA only stores the UID of the token owner. To resolve the complete user, this endpoint is used. If an error occurs, the resolver will only log it and not throw an exception.
Possible tag: {userid}
Get User by Name
Configure the endpoint to retrieve a single user for the username. If an error occurs, the resolver will only log it and not throw an exception.
For example, this is used when a user tries to authenticate against privacyIDEA. To resolve the complete user and evaluate if the user exists, this endpoint is used.
Possible tag: {username}
Create User
Configure the endpoint to create a new user in the user store. The above-defined attributes can be set in the UI and
will be added to the request body. Additionally, you can define a password that must be specified in the request
mapping using the tag {password}.
All user attributes defined in the attribute mapping can be used as tags, e.g. {username}, {userid},
{givenname}, {surname}, {phone}, {mobile}, {email}.
Edit User
Configure the endpoint to edit an existing user in the user store. The above-defined attributes can be set in the UI
and will be added to the request body. Additionally, you can define custom request parameters in the request mapping.
All user attributes defined in the attribute mapping can be used as tags, e.g. {username}, {userid},
{givenname}, {surname}, {phone}, {mobile}, {email}.
Delete User
Configure the endpoint to delete an existing user from the user store.
Possible tag: {userid}
5.1.5.3. Entra ID Resolver¶
Added in version 3.12.
The EntraID resolver is a preconfigured advanced HTTP resolver to retrieve user information from Microsoft Entra ID. Check out the Microsoft Graph API documentation if you want to change the default configuration. The configuration is similar to the advanced HTTP resolver. In the following, only the differences and some default settings are described.

Generic Settings
Base URL: The base URL of the Microsoft Graph API. It will be concatenated with the
Endpointin the detailed configurations. By default, this ishttps://graph.microsoft.com/v1.0.Attribute Mapping: The mapping between privacyIDEA user attributes and the ones used by Entra ID are already all prefilled. If you do not need all of them, you can remove them.
Groups: Receive the group memberships when getting the user information. Optionally, you can define the privacyIDEA user groups key to store the groups in the user info. By default, this is
groups. You can also define the user store group attribute to specify which Entra ID attribute should be used as an identifier for the group. By default, this isdisplayName.Edit user store: By default, editing the users in Entra ID is not enabled. If you want to enable this option, you need to ensure that the required write permissions are granted to the privacyIDEA server in Entra ID.
Verify TLS: By default, the TLS certificate of the Entra ID server is verified. Usually, there is no need to add a custom certificate.
Authorization
To access the Microsoft Graph API, the privacyIDEA server must authenticate against Microsoft Entra ID. First of all, you need to register the privacyIDEA server as an application in the Microsoft Entra admin center:
Browse to Identity > Applications > App registrations and select New registration.
Enter a name for the application, e.g. “privacyIDEA” and select Register to complete the app registration.
For more information, read the official documentation on how to Register an Application in Microsoft Entra ID.
Afterwards, you need to grant permissions to your application:
On the application page, browse to API permissions and select Add a permission.
A new window opens. Select Microsoft Graph and then Application permissions.
On the bottom, different scopes with possible permissions appear. Open the User section and select the permissions you want to grant to the privacyIDEA server:
User.ReadBasic.All: Allow privacyIDEA to read the basic profile information of all users in the tenant. This includes the username, user ID, given name, surname, and email. If this information is sufficient and you do not need to create, edit, or delete users, you can select this permission.
User.Read.All: Allow privacyIDEA to read all user profiles in the tenant. Select this permission if you want to use the resolver only to read user information, but not to create, edit, or delete users.
User.ReadWrite.All: Allow privacyIDEA to read and write all user profiles in the tenant. If you want to use the resolver to create, edit, or delete users, you need to grant this permission.After selecting the permissions, select Add permissions to add them to the application.
If you want privacyIDEA to check the user’s password, you need to add another permission: Go to Microsoft Graph > Delegated permissions > OpenId Permissions and select openid
After adding the permissions, you need to grant admin consent for the permissions. Select Grant admin consent for <tenant name> and confirm the dialog.

For more information, read the official documentation on how to Configure app permissions for a web API.
Finally, you need to specify a client credential to authenticate the privacyIDEA server against the Microsoft Entra ID. On the application page, browse to Certificates & secrets. There are two ways to authenticate:
Client certificate: Use a certificate of the privacyIDEA server to authenticate against Microsoft Entra ID. It is the recommended credential type by Entra ID. However, you can only use this credential type if the user’s password is checked by Entra ID first, and privayIDEA only evaluates the second factor. It can not be used if privacyIDEA should check the password.
To add a certificate, browse to Certificates and select Upload certificate. Select the certificate file and select Add. Supported file types are *.cer, *.pem, and *.crt.
Client secret: A static secret string (application password) that is used to authenticate the privacyIDEA server against Microsoft Entra ID. Use this credential type if the user’s password should be checked by privacyIDEA in an authentication flow.
You can create a new client secret by selecting New client secret and Add to confirm. The secret will be displayed only once, so make sure to copy it and store it securely.

For more information, read the official documentation on how to Add and manage application credentials in Microsoft Entra ID.
In the privacyIDEA web UI, in the authorization section of the EntraID resolver, you can now configure the following settings:
Authority: The URL of Microsoft where the application needs to authenticate to receive an access token. This is usually
https://login.microsoftonline.com/{tenant}, where{tenant}is the name of your tenant. You can use the tenant tag and define the tenant name below.Tenant: The name of your Microsoft Entra ID tenant
Client ID: The application (client) ID of the registered application in Entra ID. In the Microsoft Entra admin center, browse to Applications > App registrations > All applications and select your privacyIDEA server. On the application overview page, you can find the application (client) ID.
Client Credential: The client credential to authenticate the privacyIDEA server against the Microsoft Entra ID. Depending on the selected authentication method, you can either select “certificate” or “secret” for the type.
Secret: Enter the client secret you created in the Microsoft Entra admin center.
Certificate: Enter the counterpart to the server certificate that you uploaded in Entra ID.
Path to the private key file: The path to the private key file you used to generate the certificate. The key must be in PEM format.
Password of the private key: If the private key is encrypted, enter the password here; otherwise, leave the field empty.
Thumbprint of the certificate: The thumbprint of the certificate you uploaded in Entra ID. You can find the thumbprint also in the Microsoft Entra admin center on the application page. There, you need to browse to Certificates & secrets > Certificates.

Check user password
To authenticate users, the OAuth 2.0 resource owner password credentials (ROPC) flow is used. It can only be used with client secrets as credential type and not with certificates. Generally, it is recommended to let Microsoft Entra ID handle the user password check and privacyIDEA only to evaluate the second factor. However, if you want to use privacyIDEA to check the user password, you can configure the endpoint to authenticate the user with their username and password.
Check out the OAuth ROPC documentation for more information about the ROPC flow.
User List
The preconfiguration sets the consistency level header to “eventual” to enable advanced query capabilities. This allows for searching for user attributes that either start with or end with the search value. If the header is not set, we can only search for user attributes that start with the search value.
More advanced searches where the search value is contained in the user attribute are not supported by the Microsoft Graph API.
Create User
To create a user, all defined attributes from the attribute mapping are added to the request body. Additionally, the following required parameters are set in the request mapping:
accountEnabled: Set to true to enable the user account.
displayName: This is the user’s display name. By default, it is constructed from the given name and surname, such as “John Doe”.
mailNickname: The mail alias for the user. By default, this is equal to the given name.
- passwordProfile: A dictionary by default containing only the user’s password. The following options can be set:
password (required): The password for the user. You can use the tag
{password}. Note that if you do not specify a password, the tag can not be replaced, and the raw tag string{password}will be used as the password. This will cause an error as this password does not comply with the password complexity requirements of Entra ID.forceChangePasswordNextSignIn (optional): If set to true, the user must change the password at the next sign-in.
forceChangePasswordNextSignInWithMfa (optional): If true, at next sign-in, the user must perform a multifactor authentication (MFA) before being forced to change their password.
5.1.5.4. Keycloak Resolver¶
Added in version 3.12.
The Keycloak resolver is a preconfigured advanced HTTP resolver to retrieve user information from Keycloak. Check out the Keycloak API documentation if you want to change the default configuration. The configuration is similar to the advanced HTTP resolver. In the following, only the differences and some default settings are described.

Generic Settings
Base URL: The base URL of the Keycloak server. It will be concatenated with the
Endpointin the detailed configurations. By default, this ishttp://localhost:8080. However, for production use, you might need to adapt this.Realm: The name of the realm in Keycloak from which the users should be retrieved. You can use the tag
{realm}in the endpoint definitions to insert the realm name.Edit user store: By default, editing the users in Keycloak is not enabled. If you want to enable this option, you need to ensure that the required write permissions are granted to the privacyIDEA server in Keycloak.
Verify TLS: By default, the TLS certificate of the Keycloak server is verified. If you have a self-signed certificate, you can add the certificate of the CA here.
Authorization
PrivacyIDEA must authenticate against the Keycloak server to retrieve an access token. This token is then used to
access the Keycloak API to resolve and edit users. The authentication is done on behalf of a user. Hence, you need to
create a service account in Keycloak with the required permissions to read (and write) users. If you only want to
retrieve user information, the service account only requires the role view-users. If you also want to edit users,
the role manage-users is required additionally.
In the authorization section of the Keycloak resolver, you can now configure the following settings:
Username: The username of the service account in Keycloak.
Password: The password of the service account in Keycloak. It is stored encrypted in the database.
The configured username and password are used as tags in the request mapping definition. The response mapping
uses the returned access token to create an authorization header, which is then used for all further requests to the
Keycloak API.
Check User Password
In Keycloak, the user’s password is checked using the OpenID Connect token endpoint. Check out the Keycloak OpenID Connect documentation for more information.
User List
The Keycloak API only allows substring search for the username, givenname, surname, and email attributes.
If any of these attributes are used as search parameters and contain the wildcard character *, the query parameter
exact=false is set to enable substring search for these attributes.
If no asterisk is present in these attributes, the query parameter exact=true is set to disable substring
search and only return exact matches.
Note that this can only globally enable/disable substring search for all attributes.
Get user by name
There is no endpoint to retrieve a user by name. Instead, the user list endpoint is used to search for users filtered
by the user name. Additionally, the query parameter exact=true is set to only return users with an exact
match of the user name. If multiple users are found, a ResolverError is raised.
Create user
To create a user, all defined attributes from the attribute mapping are added to the request body. Additionally,
the request mapping contains the parameter {"enabled": true} to enable the user account. You can set this to
false if you want to create the user account in a disabled state.
Keycloak does not support setting the user password during user creation. This would be a separate API call to another endpoint. This is actually not implemented in privacyIDEA.
5.1.6. User Cache¶
privacyIDEA does not implement local user management by design and relies on UserIdResolvers to connect to external user stores instead. Consequently, privacyIDEA queries user stores quite frequently, e.g. to resolve a login name to a user ID while processing an authentication request, which may introduce a significant slowdown. In order to optimize the response time of authentication requests, privacyIDEA 2.19 introduces the user cache which is located in the local database. It can be enabled in the system configuration (see User Cache expiration in seconds).
A user cache entry stores the association of a login name in a specific UserIdResolver with a specific user ID for a predefined time called the expiration timeout, e.g. for one week. The processing of further authentication requests by the same user during this timespan does not require any queries to the user store, but only to the user cache.
The user cache should only be enabled if the association of users and user ID is not expected to change often: In case a user is deleted from the user store, but can still be found in the user cache and still has assigned tokens, the user will still be able to authenticate during the expiration timeout! Likewise, any changes to the user ID will not be noticed by privacyIDEA until the corresponding cache entry expires.
Expired cache entries are not deleted from the user cache table automatically. Instead, the tool
privacyidea-usercache-cleanup should be used to delete expired cache entries from the database,
e.g. in a cronjob.
However, cache entries are removed at some defined events:
If a UserIdResolver is modified or deleted, all cache entries belonging to this resolver are deleted.
If a user is modified or deleted in an editable UserIdResolver, all cache entries belonging to this user are deleted.
Note
Realms with multiple UserIdResolvers are a special case: If a user userX tries to authenticate in a
realm with two UserIdResolvers resolverA (with highest priority) and resolverB, the user cache is queried
to find the user ID of userX in the UserIdResolver resolverA. If the cache contains no matching entry,
resolverA itself is queried for a matching user ID! Only if resolverA does not find a corresponding
user, the user cache is queried to determine the user ID of userX in resolverB. If no matching entry
can be found, resolverB is queried.
Footnotes
